
Tengine支持GPU / CPU异构调度
随着深度学习的快速发展,把深度学习算法部署到嵌入式设备的需求也日益增加。
目前开源的嵌入式推理框架中,有支持ARM CPU加速推理的,也有支持GPU加速的,但这些移动端推理框架中,还没有一个框架能够进行CPU / GPU异构调度。
如今,Tengine作为ARM人工智能平台的软件框架,首次发布支持CPU / GPU异构调度。
Tengine的GPU / CPU异构调度的原理是:
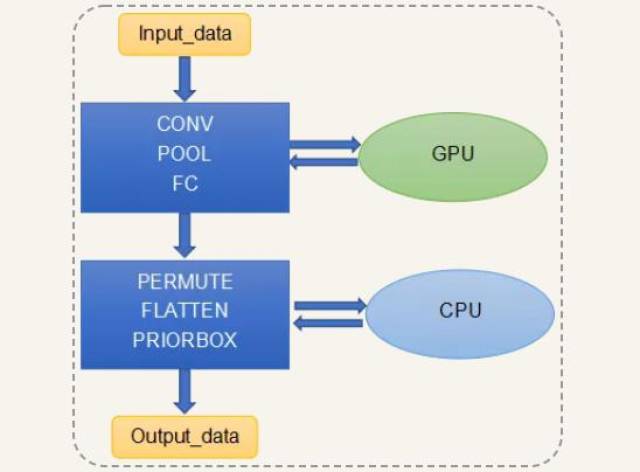
下面我们将演示,如何调用Tengine进行GPU / CPU异构调度,进行检测网络MobilenetSSD的推理加速。
我们的测试环境是Linux的测试平台是开发板萤火虫RK3399:
Tengine是通过调用Arm Compute Library(ACL)进行GPU加速,我们使用的ACL版本为18.05:
为了发挥GPU的最高性能,我们需要设置GPU的频率到最高频率:
显示的 GPU 频率应该是 800000000 。
git clone Tengine项目:
在配置文件中打开开关CONFIG_ACL_GPU = y,并指定ACL路径:
编译:
下载MobilenetSSD模型,可以从[Tengine model zoo](https://pan.baidu.com/s/1LXZ8vOdyOo50IXS0CUPp8g)(psw:57vb)下载模型〜/ tengine / models /路径下:
执行时需要设置一些环境变量:
设置GPU_CONCAT = 0,是为了避免GPU / CPU在的concat这一层在GPU / CPU频繁来回传输数据造成性能损失;
设置ACL_FP16 = 1,是支持GPU用float16的数据格式进行推理计算;
设置REPEAT_COUNT = 100,是让算法重复执行100次,取平均时间作为性能数据;
taskset 0x1用于绑定CPU0(1A53)执行程序;执行的时候需要加-d acl_opencl来打开使用gpu的开关。
从下图可以看到,GPU用半浮点精度float16的检测结果是正确的。

我们对比了 Tengine 用纯 CPU 进行 MobilenetSSD 的推理计算的性能:
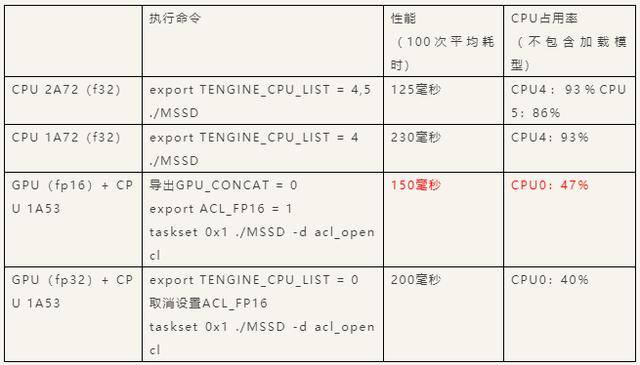
可以看出,通过GPU / CPU异构调度(GPU + 1A53)的性能大约是两个CPU大核A72的性能,且A53的占用率为50%左右。
Tengine支持的GPU / CPU异构调度,有两个方面的优势:
一方面,把NN网络中的主要算子在GPU运行,把特定算子在CPU上运行,使得开发者的开发成本大大降低,开发者可以快速通过Tengine将深度学习算法在GPU / CPU上运行起来。
另一方面,把深度学习算法跑在GPU上,其余的CPU计算资源就可以用于其他算法,比如SLAM中的特征提取,路径规划等算法,充分利用了GPU / CPU计算资源。